Statistica™
The powerful tool for data science and statistics: Prepare data, design workflows, integrate technologies & create models.
// Data science is a team sport
Democratise, collaborate and operationalise


// Prediction with Statistica
Acting with foresight
To gain predictive insights, organisations need to focus more on deploying, managing and monitoring analytics models. Smart businesses rely on platforms that support the entire analytics lifecycle while providing enterprise security and governance. TIBCO® Data Science software helps organisations innovate and solve complex problems faster so that predictive insights can be quickly translated into optimal results.
// DATA SCIENCE ON A NEW LEVEL
Your benefits using Statistica / Data Science
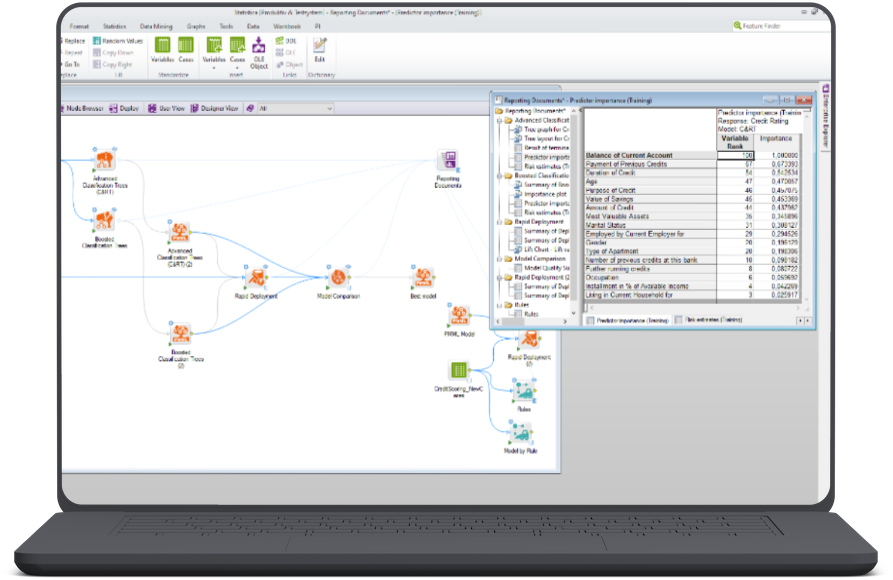
Full spectrum analyses
ML, graph/network, predictive and text analysis, regression, clustering, time series, decision trees, neural networks, data mining, multivariate statistics, statistical process control (SPC) and design of experiments (DOE) are easily accessible via built-in nodes
Machine Learning for Big Data
Automated analytics models with Big Data machine learning algorithms iteratively learn from data and optimise performance. Let your computers find new patterns and insights without explicitly programming them where to look. Learn how to deal with big data.
Teamwork
Easy collaboration allows experts, clerks, developers and data scientists and engineers to incorporate algorithms into business systems. A drag-and-drop interface makes it easy to create data preparation, analysis and scoring pipelines. Share and annotate data, scripts, models and workflows.
Monitoring, management, deployment
Model comparison with champion challenger testing. Model drift warnings and signal when to update. Deploy workflows and set them to run on schedule. Push PMML or PFA real-time scoring to Cloud Foundry, AWS or Google App Engine. Build models on EMR or Redshift and deploy them locally in Oracle or Teradata.
Security, Governance, Auditability
TIBCO Data Science software interacts with secured clusters for advanced analytics on Hive & Spark using IT data security policies. Use role-based security for all assets within the system. Built-in version control, audit trails and approval processes.
Open, flexible, extensible
Analytic pipelines extended through seamless integration with Amazon, Azure and Google ecosystems along with Python, R, Jupyter Notebooks, C# and Scala. Create custom operators that can be reused across your organisation and run directly in the database, cluster or at the edge.
Pharmaceutical Compliance with TIBCO Statistica®
In particular, TIBCO® Statistica also meets pharmaceutical guidelines: another strategic and differentiating point added to its long feature list.
// STRICT STANDARDS
Regulation of the pharmaceutical industry
To meet the stringent regulation of the pharmaceutical industry, TIBCO Statistica offers the following solutions:
Statistica Server
Statistica Server is an analytical job server with a metadata store that centrally manages database connections, queries, analysis templates, report templates and workspaces. Items can be versioned, approved and released via role-based security. Data can be cleansed and watermarked/approved for use via an approval process, review trial and annotations.
Multivariate Statistical Process Control
(MSPC) analytics designed for process monitoring and prediction of quality results.
PI Connector
The Statistica PI Connector enables direct integration with data stored in the PI Data Historian for optimised and automated analysis for applications such as Process Analytical Technology (PAT).
Product traceability
Product traceability is a solution for mapping complex (batch) processes to meaningful analytical reports and drill-downs. Integrate it with virtually any LIMS and similar systems to enable meaningful reporting and root cause analysis across selected process steps and provide flexible, high-dimensional insight into the automated manufacturing process.
Statistica stability & shelf life analysis
Statistica Stability & Shelf Life Analysis is a complete solution for validated shelf life analysis and reporting. The solution implements accepted standard approaches for single and multiple batch studies, pooled and separated estimates per batch (separate intercept, separate/common slope, probability tests) and all common shelf life estimation techniques.
// Interest awakened?
Contact us!
Do you have questions about TIBCO Data Science / Statistica and StatSoft’s services, would you like to purchase a licence or enquire about a project? Our project managers and Statistica experts are there to help you in word and deed. Get in touch with us.
